Gathering data. Every research method gathers information about a research question presented in terms of constructs based on a theory framework. For each construct, the method should state how information was actually gathered to allow others to repeat the study. It might also explain why each way was used because how information is gathered can affect the results, e.g. one can measure Fear by heart rate, pupil dilation, asking “How afraid are you?” or observing actions like running away, and the results may differ in each case. One has to do this whether the data collected is qualitative or quantitative. Qualitative research methods like action research, case study, grounded theory and ethnography all have guidelines on this. Likewise in quantitative work there are many ways to measure a magnetic field, so discuss why you chose one way over others. Discuss how and why each construct was investigated in the chosen way.
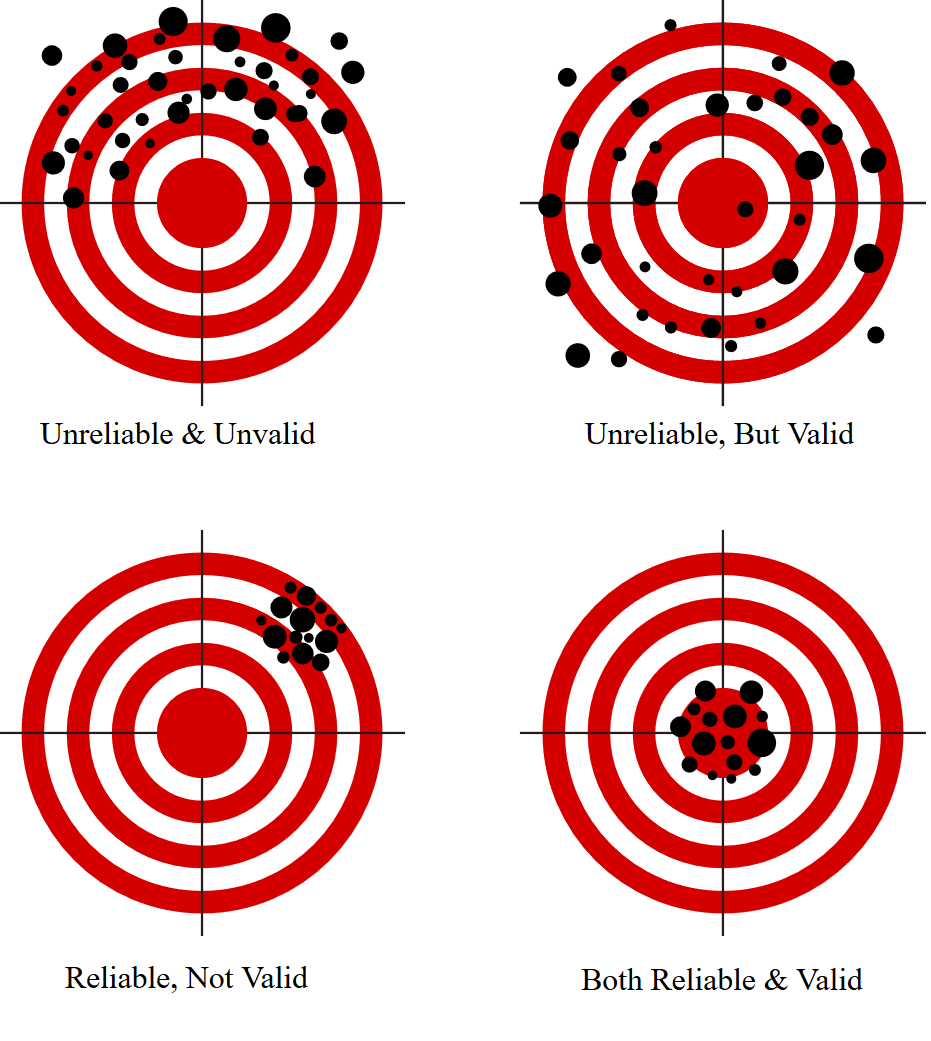
Good data. Good research is based on good data that has two properties every researcher desires:
- Validity. Validity is whether the data gathered actually represents the construct concerned, e.g. to do research on hypnosis requires a way to confirm the subjects really were “hypnotized”, else a critic could argue that they were just cooperating with the experimenter. Good research requires valid data.
- Reliability. Reliability addresses the question of whether the data gathered would be the same if gathered again, e.g. measures of blood pressure at different times of the day often vary considerably, depending on stress, food, lighting and many other things. Good research requires reliable data.
Reliability and validity are quite different concepts.
Validity. In research, it is critical that what is measured represents what it is supposed to. For example, does cranial capacity measure intelligence, as our brains are bigger than those of chimpanzees? As male brains are on average bigger than female brains, this would imply that men are smarter! Unfortunately whale brains are six times bigger than ours and the brains of Neanderthal “cave men” were about 10% bigger. So male brains are bigger because men are on average bigger not because they are smarter. To make the point, using foot size to measure intelligence would be a reliable measure but not a valid measure. Validity in research is established in three ways:
- Content validity. Is that the construct is generally agreed to be self-evident in the measure, e. g. asking “Did you enjoy the web site?” as a measure of enjoyment. Content validity is used for established constructs defined in the literature review.
- Criterion validity. Involves validating a new measure against one already accepted as valid, e. g. a web clicks “interest” measure can be validated by correlating it with purchase data. Criterion validity is used for a new measure of an established construct.
- Construct validity. Is when a new construct is deduced from existing data that “hangs together” (convergent validity) and is distinct from other data (discriminant validity), e. g. a construct like “Economic Setting” might lack construct validity if it is not a unitary variable, i.e. one thing. One can also use factor analysis to define the parts of a multi-dimensional data set that vary together.
The easiest way to ensure valid measurement is to use a tool someone else has validated. It is always important to argue why the data gathered represents what it purports to represent.
Reliability. Good data should change little when measured at different times or by different people. Reliable measures are stable and without errors caused by the measuring itself. For example, questions that different people interpret differently are not reliable. Qualitative studies use standard methods, keep detailed journals and analyze consistency to get reliability. Quantitative studies use:
- Test-retest reliability.Involves checking how a measurement changes if repeated, e. g. give a test then give it again a day later to see how much change there is using Pearson’s correlation .
- Split-half reliability checks if the measure is internally consistent with itself, e. g. compare the first half with the second half of a test, to see if those who score high on the first half also score high on the second half.
Reliability coefficients like Cronbach’s alpha are generally accepted if they are 0.85 or higher, while others like Kendall’s tau must be least 0.4. Again, to ensure a measure is reliable, use one that someone else has tested and found reliable. Whenever you measure anything, it is always important to establish that the data gathered would give similar results if it was gathered again in the same way.
Accuracy. Accuracy is how close a measurement is to its true value based on the sensitivity of the measuring instrument. It is often expressed in terms of the number of decimal points. Accuracy is not a substitute for reliability or validity, e.g. an accurate measure of blood pressure with hi-tech equipment is still unreliable if a subject’s readings vary during the day. It may also be invalid say as a measure of stress if it varies with activity that is not stressful. It is misleading to use more decimal points than the data reliability supports, e.g. “33.333% of the rats responded to the treatment, 33.333% did not, and the other one escaped during the experiment.”
Missing Values. Missing values occur when a data gathering attempt fails. Attempts to gather data can give three outcomes:
1. A successful response.
2. A nil response (NR).
3. A not applicable response (NA).
Where NR and NA are missing values. For example, when asked “Why did you buy your mobile phone?” the subject may give some reason (a successful response), they may walk away as they don’t want to answer (a nil response), or may say “I don’t have a mobile phone” (a not applicable response). It is important to record missing values as they are also data and may also have implications. Report how missing values were recorded in the data.
Unit of Research. The unit of research is the data collection unit, i.e. one data collecting act or “case”. Often the unit of research is the subject but it can be other things, e.g. in an online group voting study, the case could be a vote (choice measure), an individual (satisfaction measure), or a group (agreement measure). The difference shows in the raw data table, where the columns are variables and each row is a case, e.g. if the rows are people then one person is one case but if they are votes then the vote is the case. The case affects the number of measurements (N) of the analysis, e. g. 90 subjects could give 900 votes (N=900), 90 satisfaction ratings (N=90 people), or 18 five person group agreement ratings (N=18 groups), depending on the case. Unless it is obvious, state clearly the unit of research of the study.